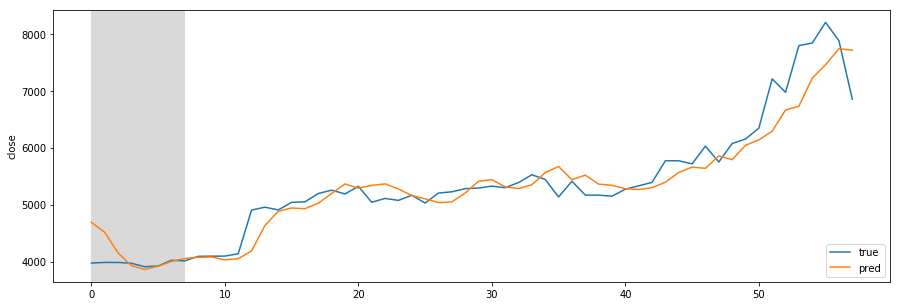
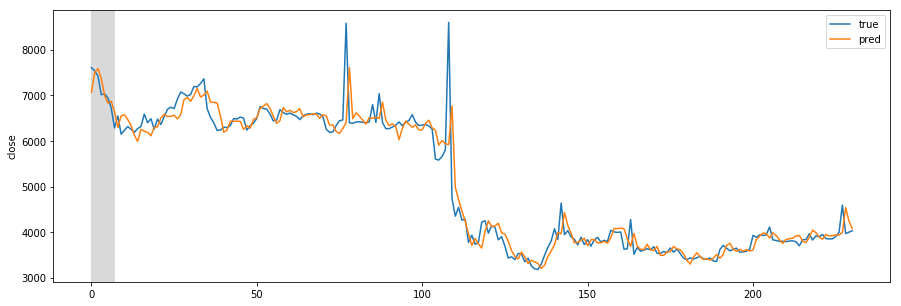
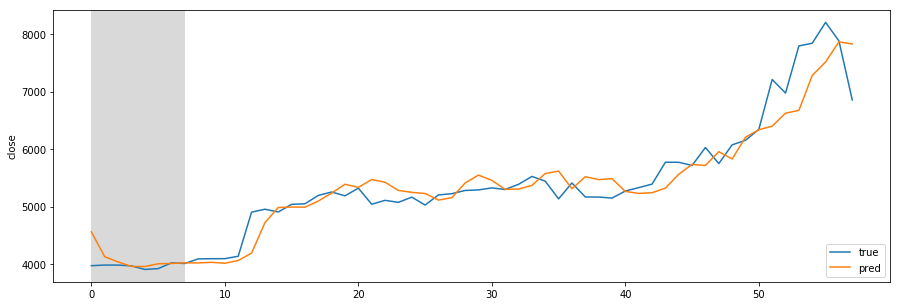
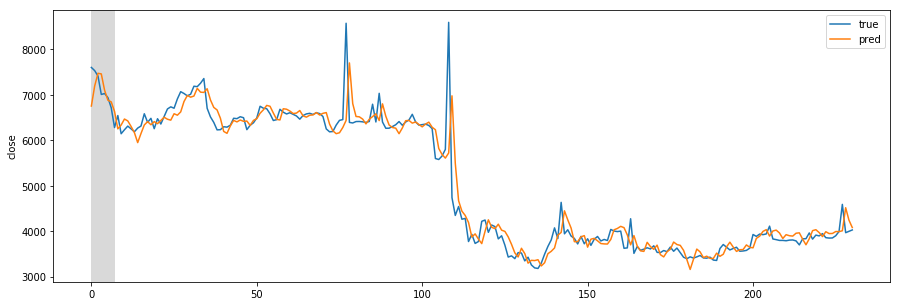
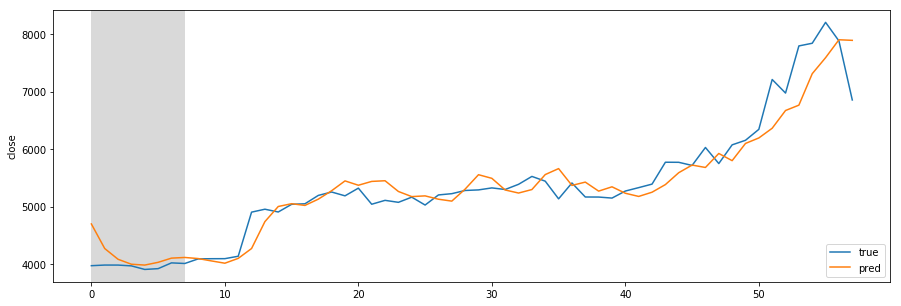
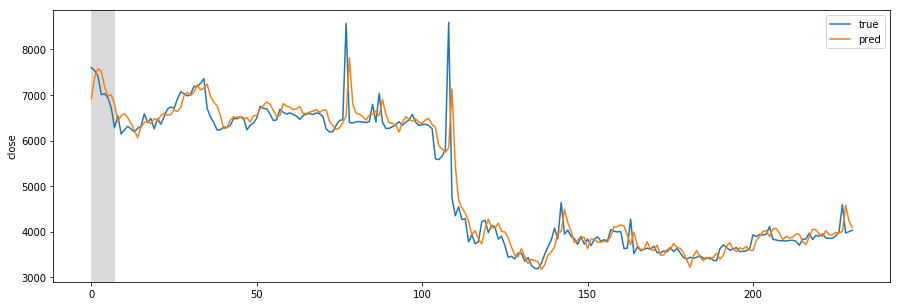
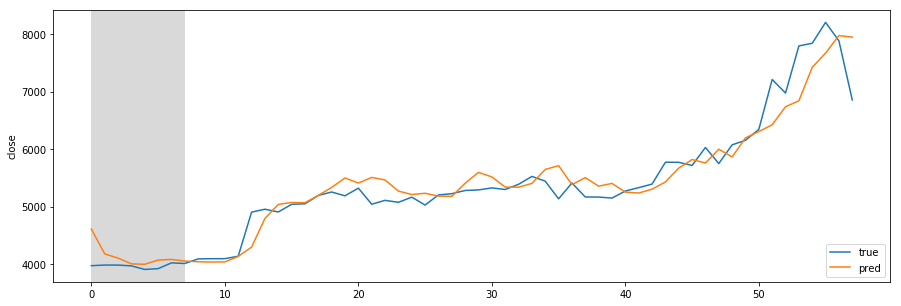
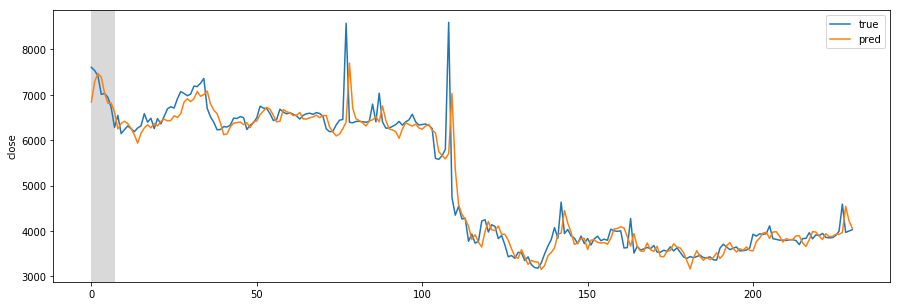
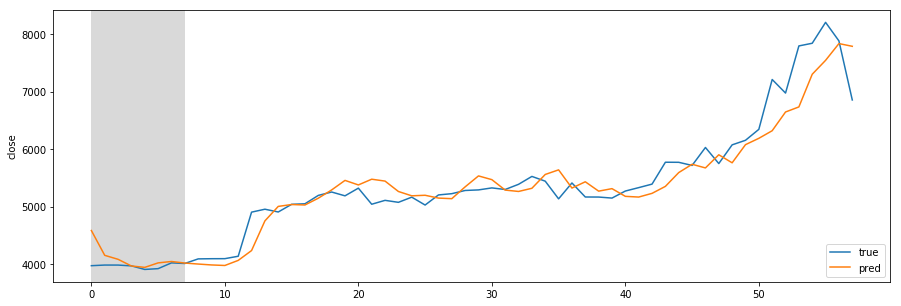
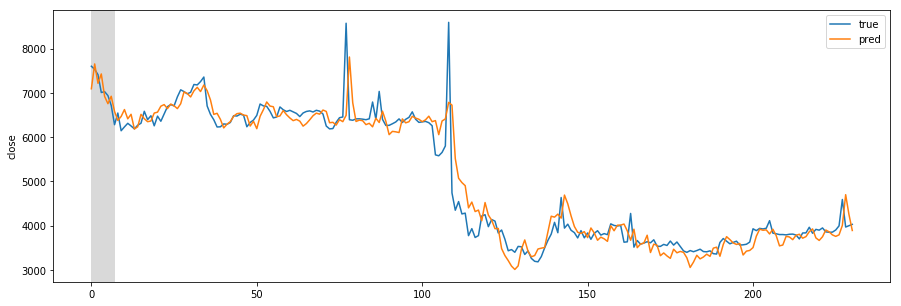
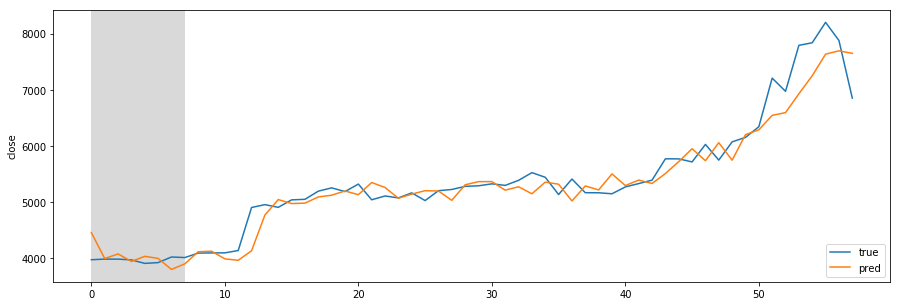

Missing Authorization header in Angular 7 HTTP response
Accessing an API back-end from Angular client may result in missing response headers. A common scenario is a missing Authorization header, containing the JSON Web Token (JWT) which is returned from the back-end service when the user logs in successfully.

MVVM’s Model implementation in Android application. Room
As we said in the previous article Model is the data in our application. These are classes representing objects that we persist in our database or that we get from network calls to services.

Dependency Injection with Spring 5
As we learned in the previous chapter dependency injection is a very powerful technique. DI is provided by the Spring 5 Framework implementation of the Inversion of Control (IoC) principle.