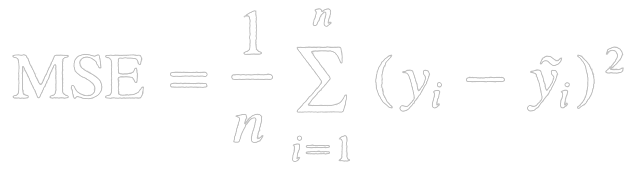
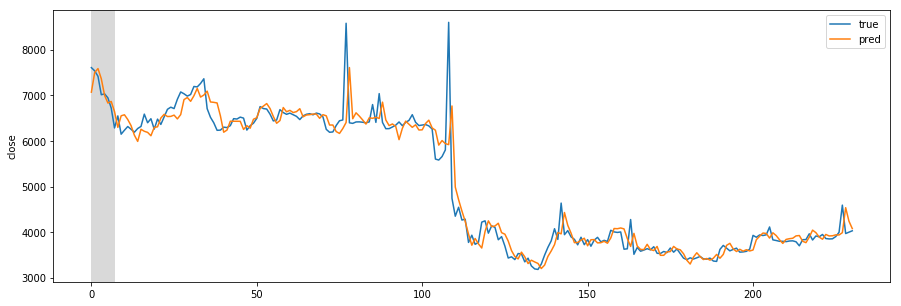
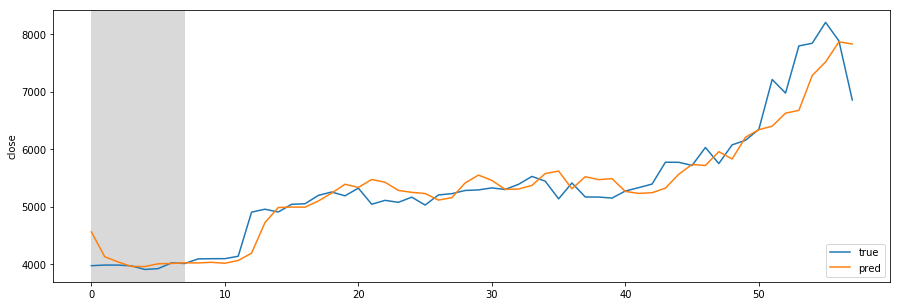
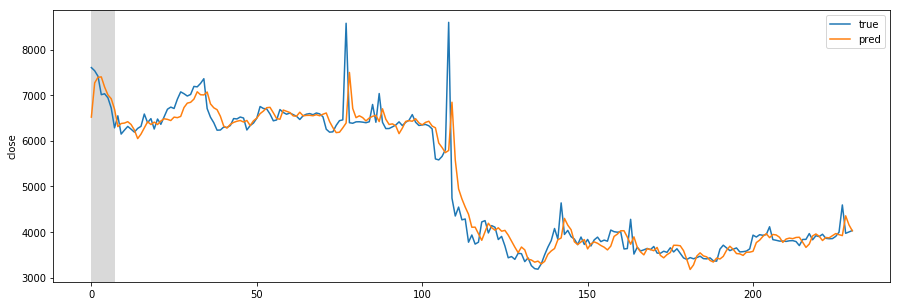
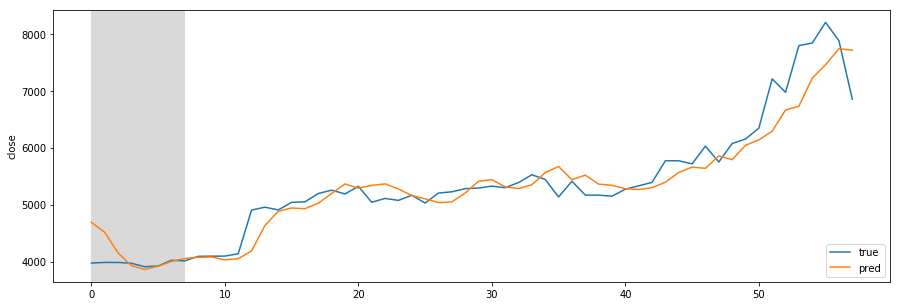
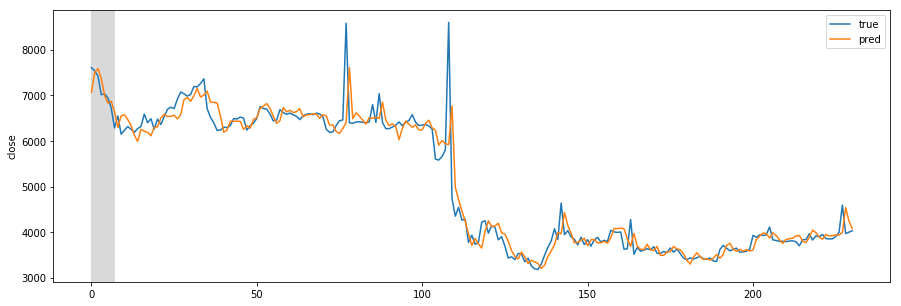
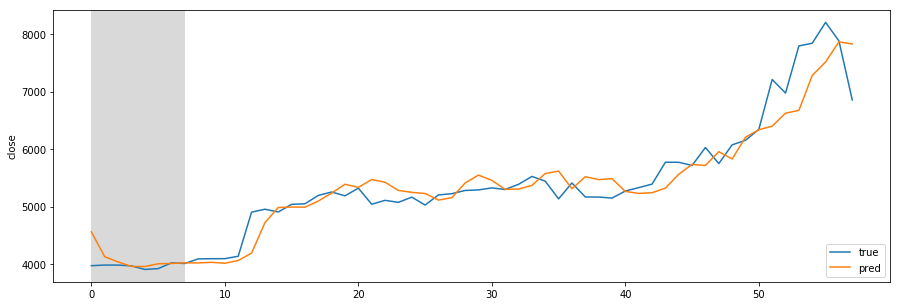
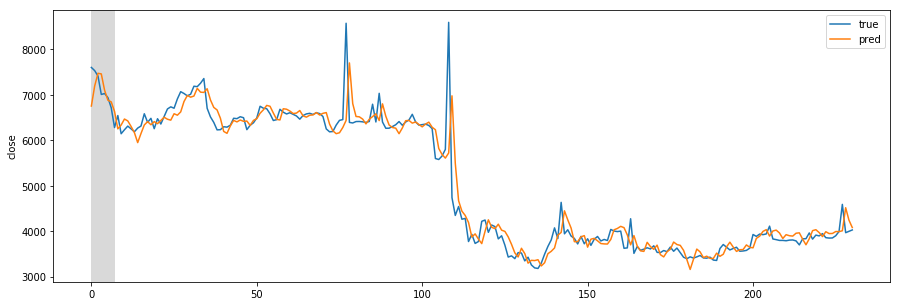
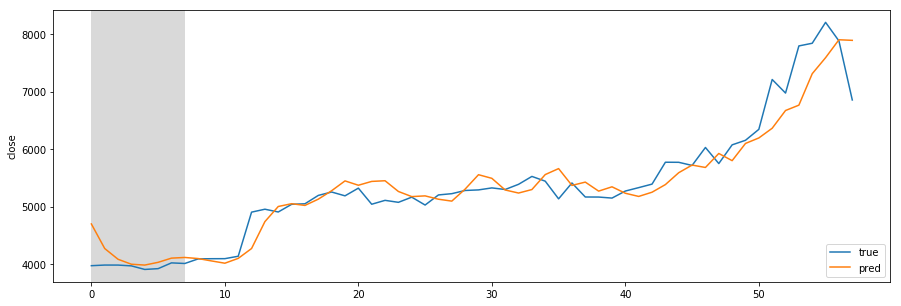
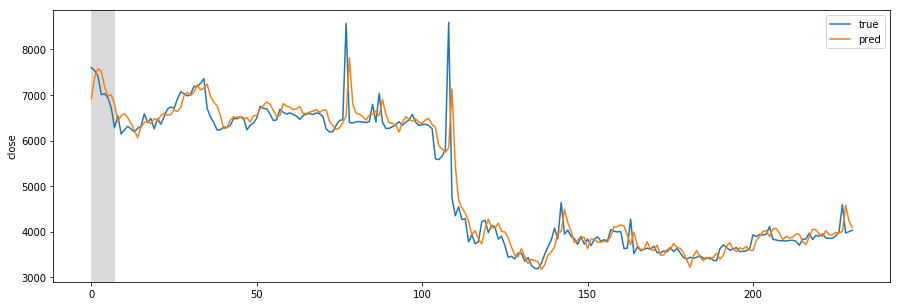
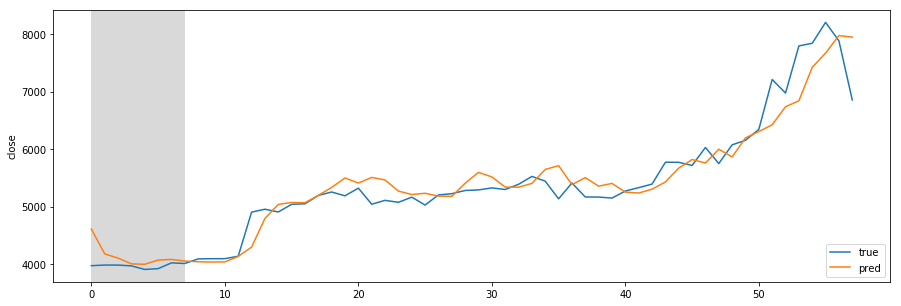
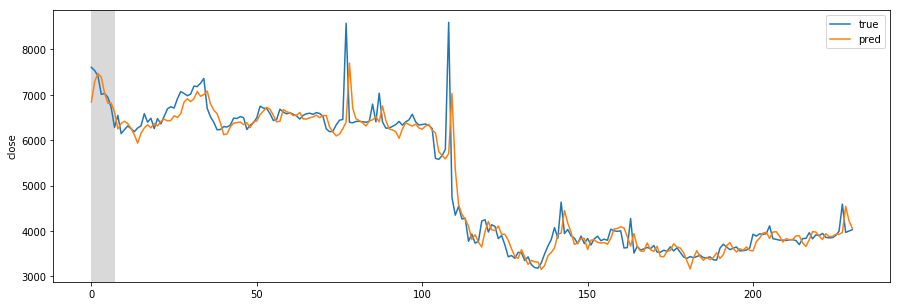

Designing REST API architecture
The web layer is the top layer in the architecture. It is responsible for processing user queries and returning back responses to the user. These operations happen in the controllers.

Room. Reactive queries
Room has great integration with LiveData. Results from SQL queries can be easily wrapped in LiveData container. This way LiveData can be observed in the UI. When the data is changed in the database, all active observers get notified and update the corresponding views.

View in the MVVM architecture
The View component in the MVVM architecture are the UI controllers – Activities and Fragments. They should be as free as possible from any business logic. Their role is to present the data, not to transform it.